本教程视频已同步到B站: 程序员的C——实用编程,不玩虚的!
基础语法
简单数组
把具有相同类型的若干个数据按一定顺序组织起来,这些同类数据元素的集合就称为数组。数组元素可以是基本数据类型,也可以是结构体类型。注意,C语言中的数组与其他编程语言的数组或列表有相似性,但本质上又有不同。
声明数组
// 声明格式:类型 数组变量名[长度]
// 声明数组时需指明元素类型和长度(元素个数),且[]中的长度必须为常量
int arr[10];
初始化数组
C语言数组在使用前应当初始化,否则数组中的数据是不确定的,由此会造成一些不可预知的问题。
// 声明的同时,使用字面量初始化。即大括号初始化
int arr[10] = {0,1,2,3,4,5,6,7,8,9};
// 可以只指定部分元素的值,剩下的元素将自动使用0值初始化
int arr[10] = {0,1,2,3,4}; //数组元素:0,1,2,3,4,0,0,0,0,0
// 使用大括号初始化时,中括号中的长度可以省略,编译器将按照实际的个数来确定数组长度
int arr[] = {0,1,2,3,4,5,6,7,8,9};
// 不需要指定每个元素具体值,仅做零值初始化时,可以使用如下写法
int arr[10] = {0}; // 数组的每个元素都会被初始化为0
需要注意,使用大括号初始化数组时,大括号中不能为空,至少要写一个值。如int arr[10] = {}; 语法错误!
下标访问
要访问数组中的任意一个元素,都可以通过数组下标访问。因为数组是有顺序的,下标就是元素的序号。但是要注意,数组的第一个元素的序号是0,也就是说下标是从0开始的。
int a[6] = {12,4,5,6,7,8};
// 打印数字中的元素。使用: 数组变量[下标]的格式获取元素
printf("%d \n",a[0]);
printf("%d \n",a[1]);

遍历数组
int a[6] = {12,4,5,6,7,8};
// 使用for 循环来访问数组中的每一个元素
for(int i=0;i<6;i++){
printf("%d \n",a[i]);
}
// 使用for循环修改数组元素
for(int i=0;i<6;i++){
a[i] = i+2;
printf("%d \n",a[i]);
}
要注意,在访问数组元素时,[]括号中的下标可以是整型变量。
计算数组长度
虽然我们可以明确的知道数组的长度,但有时候我们需要编写更友好更易于维护的代码,例如数组的长度经常修改,则我们需要修改每一处使用数组长度的地方,不易于维护,因此我们需要能动态的计算出数组长度,而不是将长度写死。
前面我们已经多次使用过sizeof运算符,该运算符可以获取类型或变量的内存大小,那么我们可以使用它获得数组总内存大小(即数组占用多少内存),然后用总内存大小除以每一个元素占用的内存大小,就可以获得数组的长度了。由于数组存放的都是同一种类型数据,因此每一个元素占用的内存大小都是固定且相等的。
int a[6] = {12,4,5,6,7,8};
// 计算数组长度。数组总内存大小/每个元素内存大小
int len = sizeof(a)/sizeof(int);
for(int i=0;i<len;i++){
printf("%d \n",a[i]);
}
如上例,当修改数组大小时,只需要修改数组a的声明大小,其他地方不需做任何修改。
数组使用小结
- 声明数组时,数组长度必须使用常量指定(C89语法,C99支持变长数组)
- 数组应当先初始化再使用
- 数组的下标(序号)是从0开始的
- 访问数组时必须做边界检查。例如数组a的长度为5,则使用
a[5]访问是错误的。a[5]表示的是数组的第6个元素,访问超出数组长度的元素会导致程序异常退出。如果数组长度是n,则当a[i]访问时,应当保证i < n
字符与字符串
如果对于字符、字符编码这些不是非常清楚,或者说是一知半解,建议先看看博主的另一篇科普文章,对与字符与字符编码有了更深入的理解再学习以下内容
字符编码的前世今生——一文读懂字符编码
char 字符
C语言中字符是非常简单的,同时也意味着非常原始!
// 声明一个字符变量
char s = 'a';
在C语言中,字符类型的字面量是单引号括起来的一个字符,注意,字符不是字符串,它只能写一个。且char类型的字符只能表示ASCII表中的字符。实际上,C语言的char就是一个整数,它的范围是0~127
char s = 'a';
char s1 = 97;
// 可以看到,s和s1打印的结果完全相同
printf("%c \n",s);
printf("%c \n",s1);
// 以整数形式打印字符`a`
printf("%d \n",s);
char保存的这个整数也就是每个字符对应的编号,具体的内容我们可以查看ASCII表
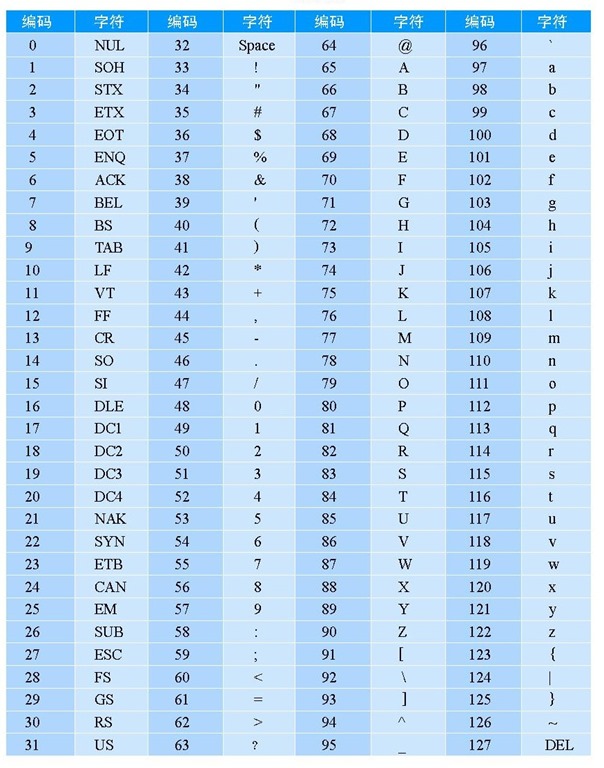
仔细观察这张表,我们可以发现一个好玩的规律,所有大写字母的编号都比它对应的小写字母小32。例如a的编号是97,则A的编号是97-32=65。发现这个规律,我们就能非常简单的实现大小写字母的转换了。
char s1 = 'c';
char s2 = 'G';
printf("%c \n", s1-32); //小写转大写
printf("%c \n", s2+32); //大写转小写
打印结果
C
g
由于char本质上是整数类型,因此可以直接进行算术运算。
宽字符
有些朋友已经发现了,char类型是C语言发展的早期,未考虑地区性字符的产物。简单说就是不能表示中文。直接char s1 = '中';这样写编译会报错的,后续当然是要出台补救措施,宽字符就是补救措施的产物。需要注意,这里宽字符概念仅作为知识拓展,这种解决方案基本被时代所遗弃,仅部分陈旧项目或某些系统内部编码使用。
#include <stdio.h>
// 使用宽字符,需包含头文件
#include <wchar.h>
int main(){
// 声明宽字符,字面量前需加上大写L
wchar_t s = L'中';
printf("size is %d \n",sizeof(wchar_t));
printf("code = %d \n",s);
}
打印结果:
size is 2
code = 20013
可以看到,这里宽字符中的编号是20013,显然一个字节是存不了这么大的整数的,因此宽字符使用两个字节来存字符的编号。这就是为什么被称为宽字符的原因,它比char要宽,使用两个字节16位表示。
在中国大陆区的Window系统中,默认使用的编码表是GBK,并且Windows还使用一种页的概念来表示编码表,而GBK编码表对应的就是page 936,也就是第936页表示GBK编码。如要查看GBK编码表,可将page 936的内容下载下来查看,链接地址 复制该连接地址,选择目标另存为即可下载该txt文件
打印输出宽字符,比直接打印char要麻烦
#include <stdio.h>
#include <wchar.h>
// 使用setlocale需包含头文件
#include <locale.h>
int main(){
wchar_t s = L'中';
// 需先设置本地的语言环境,第二个参数传"",表示使用本机默认字符集
setlocale(LC_ALL, "");
// 两种打印宽字符的方式,其中wprintf为宽字符专用函数
wprintf(L"%lc \n",s);
printf("%lc \n",s);
}
字符串 (String)
所谓字符串,顾名思义,就是将许多单个字符串成一串。既然要把多个字符串起来,当然就需要用到上面说的数组了,存放char类型元素的数组,被称为字符数组。由于C语言没有专门为字符串提供单独的类型,因此只能使用字符数组的方式来表示字符串,这是与其他编程语言很大不同的地方,也是比较繁琐的地方,如果说其他高级语言是自动挡的小轿车,那么C语言就是手动挡的轿车。
声明并初始化字符串
//1. 与普通数组相同,用花括号初始化
char str1[30] = {'h','e','l','l','o','w','o','r','l','d'};
char str2[20] = {"hello world"}; //字符数组的特殊方式
//2. 字符数组特有的方式。使用英文双引号括起来的字符串字面量初始化
char str3[20] = "hello world";
//3. 省略数组长度
char str4[] = {"hello world"};
//4. 省略数组长度,并使用字符串字面量初始化
char str5[] = "hello world";
在C语言中声明字符串,推荐以上第4种方式,它具有简洁且能避免出错的优点。
字符串与普通数组的区别
在C语言中,虽说字符串是用字符数组来表示的,但是字符串和普通字符数组仍然是不同的,这两者的区别可以简单总结为如下三点
- C语言字符串规定,结尾必须包含一个特殊字符
'\0',我们查询一下ASCII表可知,该字符属于控制字符,即无法打印显示出来的字符,它在ASCII表中的编号是0,即表中的第一个字符NUL。 - 字符串的实际长度(即字符的个数)比字符数组的长度小1。
- 声明的同时,数组只能使用花括号初始化,而字符串可以使用双引号括起来的字面量初始化。
现在通过代码验证以上结论
// 请注意,以下代码会造成无法预知的错误。不可为!
char s1[3] = {'a','b','c'};
printf(" %s \n",s1);
// 手动添加字符串结束符'\0'或整数0。正确
char s2[4] = {'a','b','c','\0'};
printf(" %s \n",s2);
//只要预留结束符的位置,编译器会自动帮我们添加,无需手动
char s3[4] = {'a','b','c'};
char s4[4] = "abc";
printf("s3=%s s4=%s \n",s3,s4);
通过以上代码验证,我们就会发现,使用char str5[] = "hello world";方式声明并初始化字符串是最好的做法,既简洁,也无需操心是否预留了字符串结束符的位置,因为编译器会自动帮我们计算好。最后再强调一次,由于字符串末尾会自动添加\0结束符,因此字符串的实际长度会比字符数组的长度小1。
声明时不初始化
char str[20];
/*
错误的赋值方式!!!
str = "abc";
str = {"abc"};
*/
// 不规范的使用方式
str[0]='a';
str[1]='b';
str[2]='c';
printf("%s",str);
以上代码是不规范的使用方式。当我们声明字符数组时未初始化就使用了,则编译器不会自动为我们添加结束符\0,使用微软的VC编译器进行编译后,直接出现了乱码情况,虽然GCC不会出乱码,但也存在不可预知的问题。
abc烫烫烫烫烫烫烫烫烫烫特3臋H?
正确的做法是在未初始化的情况下,使用字符串数组应手动添加结束符
char str[20];
str[0]='a';
str[1]='b';
str[2]='c';
str[3]='\0';
printf("%s\n",str);
当然,除了手动添加结束符号,还可以使用C语言标准库的函数来自动初始化数组。这是一种更常用的做法
#include <stdio.h>
#include <string.h> // 需要包含string.h头文件
int main(){
char str[20];
// 将数组初始化化为指定的值,这里指定0,第三个参数是数组的内存大小
memset(str, 0, sizeof(str));
str[0] = 'a';
str[1] = 'b';
str[2] = 'c';
printf("%s", str);
return 0;
}
拓展:
使用VC编译器,未初始化的数组为什么会出现“烫烫烫”?
因为VC编译器默认会干一件事情,将未初始化的字符数组,使用十六进制数0xcc进行填充
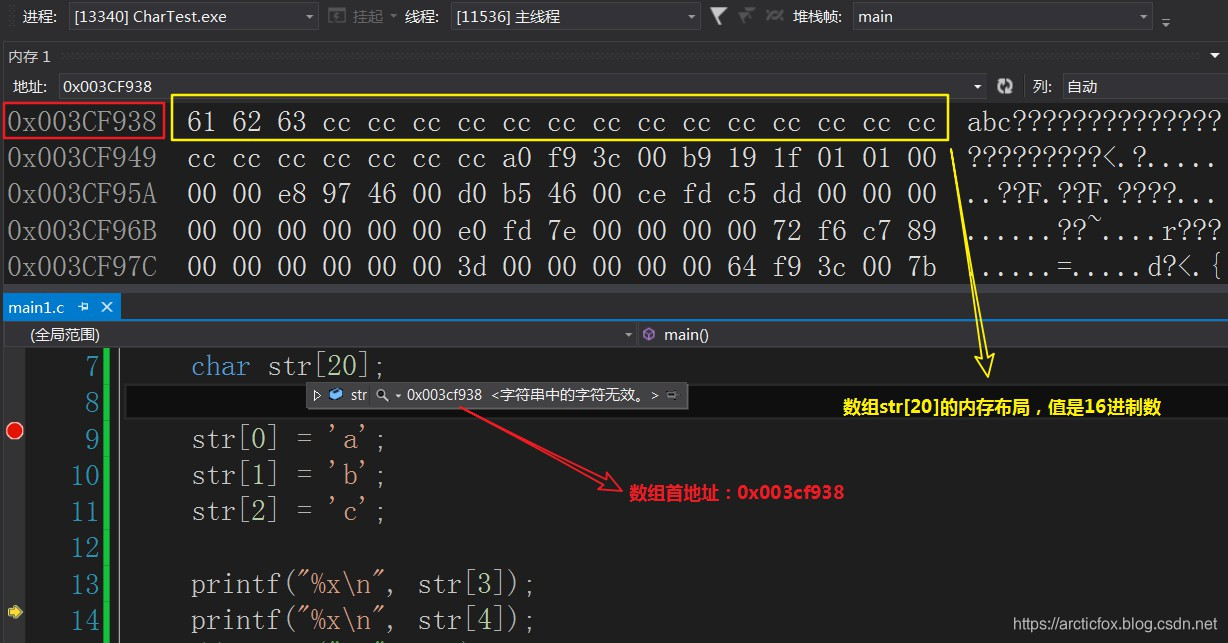
观察以上内存布局图,可知前三个元素分别是十六进制0x61、0x62、0x63,转换成十进制就是97、98、99,正好是a、b、c的ASCII码编号,剩余数组元素则默认都是0xcc,而它的十进制则是204,显然已经超出了ASCII码表的范围,Windows默认使用GBK码表,用两个字节表示一个汉字。这时候我们去查询page 936表,可发现两个cc字节合起来就是汉字烫

还可以查GBK的表,首字节cc的平面表如下,然后根据尾字节去查具体对应的汉字,这里尾字节也是cc
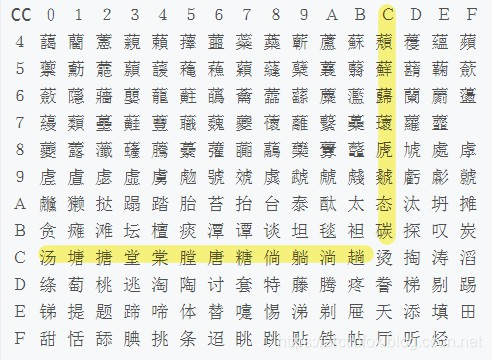
除了被填充成cc,乱码还与数组越界有关。因为没有字符串结束符\0,使用printf打印的时候,它并不知道应该在哪儿结束,因为内存都是连成一片的,超过str[20]的20个元素范围,后面还有内存空间,因此乱码 abc烫烫烫烫烫烫烫烫烫烫特3臋H?明显超出了20个char的范围,将其他的内存内容也打印了。这就好比你家住18号,你不仅把18号的门打开了,还把隔壁19号的门也撬开了。
字符串的常用函数
C语言虽然是手动挡的,但也为我们提供了一些不太完美的标准库函数,虽然这些函数多多少少都存在一些坑,但也聊胜于无,总比我们事事躬亲要强许多。要想使用字符串库函数,需要包含string.h头文件。
字符串长度
- strlen
#include <stdio.h>
#include <string.h>
int main(void){
char str[]= "hello world!";
// 动态计算str数组的长度
printf("array size is %d\n",sizeof(str)/sizeof(char));
// 获取字符串的长度
int len = strlen(str);
printf("string size is %d\n",len);
return 0;
}
打印结果:
array size is 13
string size is 12
可见str数组共用13个元素,但只有12个有效字符,最后一个为\0结束符
比较字符串内容
当我们要判断两个字符串是否相同时,是不能直接使用比较运算符==操作的
char str1[]= "hello";
char str2[]= "hello";
// ==比较的是两个数组的地址,而不是内容,结果与预期不符
printf("%d\n",str1 == str2);
- strcmp
#include <stdio.h>
#include <string.h>
int main(void){
char str1[]= "hello";
char str2[]= "hello";
// strcmp的返回值等于0时,表示两个字符串内容相同,否则不同
if (strcmp(str1,str2) == 0){
printf("str1 == str2\n");
}else{
printf("str1 != str2\n");
}
char str3[]= "bruce";
char str4[]= "hello";
if (strcmp(str3,str4) == 0){
printf("str1 == str2\n");
}else{
printf("str1 != str2\n");
}
return 0;
}
打印结果:
str1 == str2
str3 != str4
字符串的复制
- strncpy 还可使用该函数为字符数组进行初始化
#include <stdio.h>
#include <string.h>
int main(void){
char str1[100]={0};
// 将字符串复制到指定的字符数组中,并自动复制结束符。第一个参数就是目的地
// 第三个参数需指定复制的长度,这里指定目标数组的大小,表示如果超过这个长度则以这个长度为止
strncpy(str1,"Greetings from C",sizeof(str1));
printf("str1=%s\n",str1);
// 将str1的内容复制到str2中
char str2[50]={0};
strncpy(str2,str1,sizeof(str2));
printf("str2=%s\n",str2);
return 0;
}
暗坑
strncpy函数存在一个问题,如果被复制的字符串长度太长,超过了目的数组的长度,则将目的数组填充满为止,但是这种情况下就不会添加\0结束符,导致存在不可预知的问题。
#include <stdio.h>
#include <string.h>
int main(void){
char str1[10]={0};
// 字符串超过str1的长度,导致str1没有结束符
strncpy(str1,"Greetings from C", sizeof(str1));
printf("str1=%s\n",str1); // 乱码
char str2[10]={0};
// 更安全合理的做法,始终为结束符预留一个位置
strncpy(str2,"Greetings from C", sizeof(str2)-1);
printf("str2=%s\n",str2); // 字符串虽被截断,但是有结束符,安全!
return 0;
}
字符串的拼接
在其他语言中,通常只需要简单的使用+号就能拼接字符串,但是C语言就显得繁琐
- strncat
#include <stdio.h>
#include <string.h>
int main(void){
char str1[100] = "hello";
// 将第二个参数的内容追加到第一个参数的后面,相当于将两者拼接
// 第三个参数为拷贝的长度,类似strncpy,
// 这里计算数组的总长度减去字符串的长度,求得str1剩余空间的长度
strncat(str1," world!",sizeof(str1)/sizeof(char)-strlen(str1));
printf("str1=%s\n",str1);
return 0;
}
同strncpy函数相似,这里的暗坑也是目的地数组的空间不足导致丢失结束符的问题,因此应当预留结束符的位置
strncat(str1," world!",sizeof(str1)/sizeof(char)-strlen(str1) - 1);
简单函数
C语言中的函数其实是多条指令的组合单元。更通俗的说就是许多语句的组合单元。函数的好处是可以让编程结构化,而不是像早期的程序那样写成一坨。另外函数可以复用代码,这使得程序员可以少写大量的重复代码,还使得大型程序可以模块化,多人同时开发。
在国内某些教材中,例程永远只使用一个main函数,虽然这些教材也讲函数,但明显是为了讲而讲,形而上学的讲,完全缺乏实用性。有过编程经验的朋友都知道,实践工作中,C语言的函数和高级语言的类是多么重要的内容,所有的开发工作就是围绕它们展开的,因此C语言的函数内容,应当引起足够的重视。
自定义函数
在上一章我们找到了英文字母大小写转换的规律,但是我们每次使用都需要去运算,显得非常麻烦,大家已经使用过很多标准库的函数,这次我们就将该功能封装成一个我们自己的函数。
#include <stdio.h>
// 定义字符转换函数
char convchar(char ch){
if (ch >= 97 && ch <= 122){ // 小写字母范围
return ch - 32;
}else if (ch >= 65 && ch <= 90){ // 大写字母范围
return ch + 32;
}
return -1; // 不是英文字母,返回-1
}
int main(void){
char str[] = "hello";
// 循环遍历字符数组,当遍历到字符串结束符就停止
for (int i = 0; str1[i] !='\0'; i++){
printf("%c",convchar(str[i]));
}
return 0;
}
打印结果:
HELLO
我们自己编写的convchar函数功能非常简单,就是将传入的大写字母变小写,小写字母变大写。现在来看一下定义函数的格式
// 编码风格1
返回值类型 函数名(形式参数){
函数体
}
// 编码风格2
返回值类型 函数名(形式参数)
{
函数体
}
// 编码风格3
返回值类型
函数名(形式参数)
{
函数体
}
以上是最常见的三种编写函数的代码风格,由于C语言规范并不严格,还有许多奇奇怪怪的代码风格,但这里我推荐第一种,比较简洁,易于阅读,且减少代码行数,少了花括号独占的那一行,在函数较多的情况下,可以减少许多花括号的行。
需要注意,函数的返回值和形式参数都是可选的,当有返回值时,必须配合return语句返回,当函数没有返回值时,应当使用void关键字声明,注意我的措辞,是应当,而不是必须!但在我看来,任何时候都应该明确你的返回值,而不是省略什么都不写,这是C语法的缺陷,相当不严谨的地方。当然,这也是历史遗留问题,谁让C语言是编程界的老古董呢。C89中,当省略返回值时,会默认函数的返回值为int类型。以下代码是可以正常编译运行的。
#include <stdio.h>
main(){
printf("hello world\n");
return 0;
}
要注意,没有返回值时应当写上void,但没有形式参数时,可以省略,也可以写上void,不过建议省略,保持代码简洁明了。
// 无返回值,无形参
void printError(){
printf("this is error!\n");
}
// 求和函数。形式参数的声明,与普通变量声明相似,有几个就声明几个
int sum(int a,int b,int c){
return a + b + c;
}
调用函数
#include <stdio.h>
int sum(int a,int b,int c){
return a + b + c;
}
int main(){
// 函数调用,在小括号内传入实际的参数,以替换形式参数
int r = sum(1,2,3);
printf("%d\n",r);
return 0;
}
函数的声明
在C语言中,出现了两个概念,声明和定义。除了C/C++,在很多高级语言中,声明和定义基本是等同的,大量不了解C语言的程序员也是这么看待的,那么声明和定义到底是什么,有什么区别呢?先看下面的例子
#include <stdio.h>
int main(){
printError();
return 0;
}
void printError(){
printf("this is error!\n");
}
以上代码在VC编译器等其他一些编译器会直接报错,而在GCC编译器只会报警告,仍可以编译运行。大家会发现,这是因为我们自定义的函数写在main函数之后,编译器通常从上往下扫描代码,当扫到printError()时,会发现并不认识它,有些人会想当然的认为报错是因为编译器不认识该函数产生的,而实际上是报的重定义了不同的类型错误。简单解释一下,当编译器扫描到未定义的函数时,编译器会自以为是的给你进行一个隐式声明,但是编译器并不知道函数的返回值和具体的形式参数啊,这时候它就会简单猜测一下,默认你的返回值是int,然后根据你调用函数时传的参数简单分析一下形参的类型,Ok,然后编译器继续往下扫描,这时它发现了你写在后面的printError函数,可是刚刚已经给你隐式声明了一次int printError(),结果发现你的实现是void printError(),和声明对不上,返回值类型不一致,那么你的函数实现当然不被认可,编译器认为你在重新修改函数声明。有些聪明人就想,既然这样,那我定义一个int printError()函数,它的返回值刚好就是int,这样编译器的隐式声明不就能猜对返回值了吗?不错,具有int类型返回值的函数定义,形参又比较简单,编译器确实能帮你成功的隐式声明,但这种小聪明是绝不推荐的。
那GCC为什么只警告不报错呢?这是因为GCC编译器已经是现代编译器中最强大的存在,它具有一定的代码智能优化能力,你的某些错误,它帮你兜了。但这种错误是绝不应该犯的,实际中绝不能写这样的代码。出于某些原因,我们想将函数的具体定义写在main函数之后,正确的姿势应当是怎样的呢?
#include <stdio.h>
// 在main函数之前先声明
void printError();
int main(){
printError();
return 0;
}
// 在main函数之后再定义
void printError(){
printf("this is error!\n");
}
可以看到,函数声明时是不需要花括号包含的函数体的,只需要包含返回值类型、函数名、形式参数即可。但是要注意,小括号后面的分号是不能省略的。
以上示例就是将函数的声明与定义分开,在实际开发时,这些函数声明也并不是像这样直接写到main函数之前的源码中,而是写到头文件中,由于我们还没有讲到头文件,具体内容在后面的部分再说。
函数的作用域
这里简单说说作用域的问题,在函数中声明的变量被称为局部变量,只在当前函数体的范围内可被访问,离开该函数体的范围就不可被访问了。而在函数外的声明的变量,称为全局变量,全局变量在整个程序中都可被访问,也就是所有的源文件,包括.c和.h文件中都可被访问。具体细节,在后续篇幅中会详细说明
简单函数的小结
- 函数不能返回数组,因此函数的返回值不能是数组类型。
- 函数没有返回值时,也应当写上
void明确返回值类型 - C语言没有函数重载概念。这意味着C中相同作用域内的函数绝不能同名,哪怕返回值和形参都不同。C语言还没有命名空间的概念,这两者综合一起就是C语言最大缺陷之一。
- C语言函数的声明与定义是分离的,但是在任何时候都应当先声明再实现。这里声明是指显式声明。意即,当自定义的函数被定义在
main函数之前时,它同时包含了声明与定义。
关于形式参数与实际参数的概念理解
C语言的实参与形参之间是值传递,简单说就是值拷贝。在调用函数传参时,实际参数的值被复制了一份,拷贝给形参。因此形参与实参本质上就是两个变量,不可等同,它们仅是值相同。就如一对双胞胎小姐姐,即使长得像,穿着相同的衣服,那也还是两个人。
改进字符大小写转换函数
这里将之前的字符大小写转换函数做改进,使之能直接转换字符串的大小写
#include <stdio.h>
#include <string.h>
/*
当数组作为形参时,不能对其使用sizeof运算符
flags: 值为0时,全部转小写,非0时,转大写
*/
void convstr(char ch[], int flags){
for (int i = 0; i < strlen(ch); i++){
if (ch[i] >= 97 && ch[i] <= 122){
if(flags) ch[i] = ch[i] - 32;
}else if (ch[i] >= 65 && ch[i] <= 90){
if(!flags) ch[i] = ch[i] + 32;
}
}
}
int main(){
char str[] = "Hello,ALICE";
convstr(str,0);
printf("%s",str);
return 0;
}
打印结果:
hello,alice
这里需特别注意,在C语言中,凡是数组做函数参数时,都是指针传递。其他基本数据类型做函数参数,包括结构体,都是值传递。网上存在很多错误的言论和资料,一定要明确,在C语言中,数组不存在值传递,这也是为什么不能对做函数参数的数组使用sizeof运算的原因所在,因为它会自动退化为指针。
简单指针
#include <stdio.h>
// 计数器
void counter(int count){
count += 10;
printf("count=%d\n",count);
}
int main(){
int t = 0;
counter(t);
printf("t=%d\n",t);
return 0;
}
打印结果:
count=10
t=0
如上示例中,counter函数为一个计数函数,每次调用都将传入的值加10,可是为什么在函数的外部打印t值,它的值没有发生改变呢?
什么是指针
在回答什么是指针之前,我认为应当先提问为什么需要指针?如果没有明确的应当重视的理由,大家何必花大力气学习它呢?
要说清这个问题,我们先举一个简单例子:
在生活中,我们往往通过网盘来分享视频,而不是直接将本地硬盘上的视频文件发送给对方,这是因为视频文件通常会非常大,直接通过网络发送十分不便(涉及上行网速和下行网速),效率低下。
一来,在发送大文件时,作为发送者的我们必须一直开着电脑,而不能中断发送,这个过程可能需要一两个小时
二来,当我们需要将本地视频发送给多人时(在不同的时间和地点),我们每次都需要重复上述的缓慢发送过程
最后,如果我们自己制作或者修改视频时,也仍然需要重复以上过程。
现在有了网盘,我们只需将视频文件上传一次到网盘中,生成一个地址链接,每次仅分享这个链接即可。当我们修改了视频,或者增加了新视频,仍然放到以前的链接下,甚至不需告知其他人,其他人在访问链接时,自动访问的就是最新的资源,这样大大提供了效率。
现在我们明白了生活中的道理,再看指针就非常清晰了,C语言中的所谓指针的概念,简单理解相就是数据在内存中的地址,就相当于以上例中的链接,有了这个链接,我们就能找到共享的资源。我们需要C语言,需要指针,就是为了这极致的性能和效率,这是除了C/C++外的其他高级语言所不具备的。即使是号称继承自C语言的Go语言,它的指针也远没有C指针强大。当然,如果剑过于锋利,剑法却太生疏,则会未伤人先伤己,这也就是人们畏惧指针的一个原因。
如何理解内存
理解了抽象意义上的指针概念,接下来看看,计算机中的内存又是怎么回事?
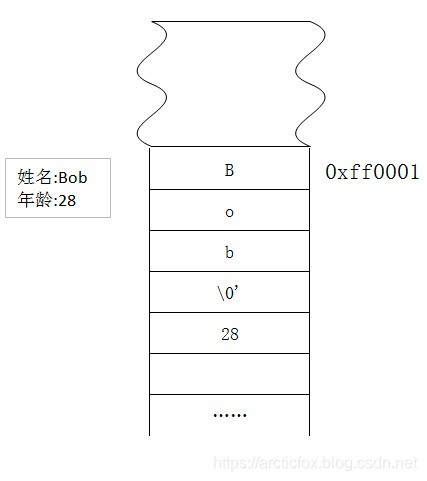
在计算机中,内存就是是一片线性的连续的小格子。每个格子的大小都是1字节,且每个格子都有一个编号,这个编号就被称为内存地址。如同现实生活中的门牌号。
当我们需要往内存中存数据时,操作系统就会随机的从这一片连续小格子中给我们分配一些可用的。例如我们要将上图中左边的信息存入内存,则操作系统会根据我们的要求,给我们分配一段空间,假设给了8个小格子,那么操作系统就会将这段空间的起始地址返回给我们,如0xff0001。在存数据时,操作系统只关心两件事,一个是分配给你的起始地址,一个是分配的格子的长度。当char name[]="Bob";时,操作系统按数据的类型依次将数据往内存中存放,而数组名name即代表地址0xff0001,接下来char age = 28;,我们这里使用一个字节保存整数28,这时,变量age的地址则是0xff0001+4。在一段内存中,除了给出首地址,其他地址都是通过这种首地址+偏移量的方式来表示的。因此才说,操作系统只关心起始地址和分配的内存空间长度。如果我们在存放一个学号int num=1000;,则地址继续往后偏移。由于int类型是4字节,因此变量num需要占用四个小格子。每个小格子都存放这个32位整数中的8个位。
理解了内存的原理,那么我们就会明白,为什么几乎所有的编程语言中都指明字符串是不可变对象。如上图,字符串name存的是Bob,这就相当于一个萝卜一个坑,如果修改为Bruce,则会超出原来的格子,从而强占变量age的格子,覆盖掉了age的值,造成这一片内存区域的混乱。
指针的使用
严格的说,C语言中的指针类型,是指保存的值是内存地址的变量。
int num = 10;
//声明指针类型变量
int *ptr;
//给指针类型变量赋值
ptr = #
printf("ptr=%x\n",ptr);
printf("num=%d\n",*ptr);
打印结果:
ptr=22fe44
num=10
上例中,int *ptr;,变量ptr就是指针变量,与普通变量的区别就是多了一个星号。实际上如果换种写法大家可能一眼就理解了:int* ptr;,将int和*紧挨,把它们看成一个整体,那这个整体就是指针类型,这样就复合我们最初学习的声明变量的格式了:【数据类型】【变量名】。实际上这样写是可以的,但是千万不要这样写,请将星号和变量紧挨一起,不要和类型挨在一起,虽然这很反直觉,但这确实是C语言的潜规则,当大家都这样写的时候,最好还是遵守规范。这样写并不是心血来潮,确实能避免犯一些错误。
这里还要学习两个运算符
-
取地址运算符
&顾名思义,就是可以获得一个变量在内存中的地址。内存地址是一个4字节的数值,通常用16进制显示,如上例中的
22fe44,它表示变量num的值储存在内存编号为22fe44的空间中。 -
间接寻址运算符
*以上第10行代码中的星号是间接寻址运算符,它只能对指针变量使用,表示将该指针变量保存的地址对应的内存中的值取出来。这样说比较绕,换个说法,如果直接将一个内存地址对应的内存中保存的值取出来,这就叫直接寻址,如果是对保存地址的变量使用,这就是间接寻址。使用间接寻址运算符的过程被称为解引用。
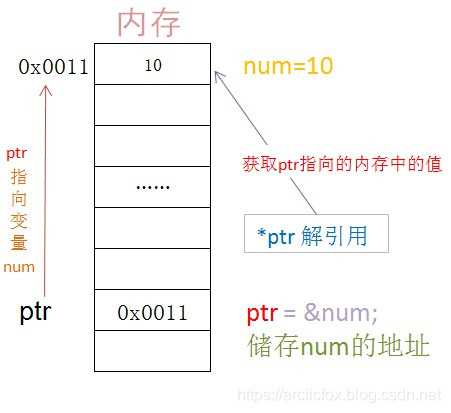
注意,指针变量的右值应当是一个地址,而不能是其他值。因此给指针变量赋值时,先使用取地址符&求得变量的地址,然后才将这个地址赋给指针变量,这个过程称为指针指向某某变量。根据指向的目标变量的类型不同,指针变量也应当声明为相应的类型。例如,指向char型变量,则应声明为char *p;。另一个重要的原则是先初始化,后使用。我们上面的例子是不规范的典型,前面我们已经说过多次,C语言中,变量应当声明后立即初始化。
那么指针变量如何在声明时初始化为零值呢?
//指针应在声明同时初始化为NULL
int *ptr = NULL;
//注意,ptr才是指针变量,而不是*ptr,切记!
ptr = #
如果直接访问未初始化的指针,会造成无法预知的后果,这种指针也被称为野指针!
简单指针的小结
- 声明指针变量时,星号应紧靠指针变量,并在同时初始化为
NULL - 指针变量的值应当是一个地址
- 声明指针类型时的星号和解引用时的星号意义完全不同,注意区分,不要混淆。声明指针类型时的星号,代表指针类型,解引用时的星号是
间接寻址运算符
使用指针改进计数器示例
#include <stdio.h>
// 形参是声明,这里*表示的是指针类型
void counter(int *p){
//此处*表示解引用
*p += 10;
printf("count=%d\n",*p);
}
int main(){
int num = 10;
// 直接初始化
int* ptr = #
counter(ptr);
printf("num=%d\n",num);
return 0;
}
实际上指针并不难,很多人觉得难,其实就是因此这里的星号写法设计得不合理,极易造成歧义,如果没有熟练指针的运用,那么星号总会给人别扭的感觉,时而会看错。要想快速熟练掌握指针,要学会经常画内存图,一旦发现迷糊了,赶紧画图,多画几次图,大脑建立了概念,就不会再出错。
关注我的公众号:编程之路从0到1




